ChatGPT and Claude are impressive. But “impressive” isn’t the same as “right for the job.” There is a key difference between ambiguous sourcing and probabilistic guessing and decision-grade data.
Every week, insights teams ask: “How is Presto different from ChatGPT?” It’s a fair question. On the surface, the outputs may look similar, but Presto was built with a very different mission: turning consumer data into actionable insight storytelling.
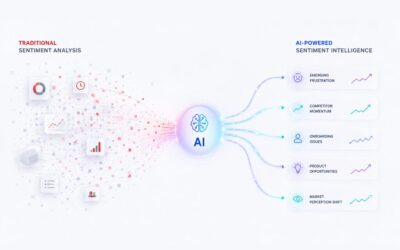
General-purpose AI models can summarize, write, and answer nearly anything with confidence. But when your business depends on understanding whether your brand is gaining ground, which ingredient is about to trend, or how your latest product stacks up against competitors, “impressive” isn’t enough. Accurate is. You’re making multi-million dollar decisions and you need decision-grade data.
Before diving into the details, we recommend watching this short video on Presto and what it does, as it gives a clear overview of how it turns consumer intelligence into faster, more confident decision-making.
Here’s why Presto, i-Genie.ai’s agentic consumer intelligence platform, is in a class of its own, and why that difference matters for enterprise decision-making.
Presto has access to consumer data that doesn’t exist on the open web
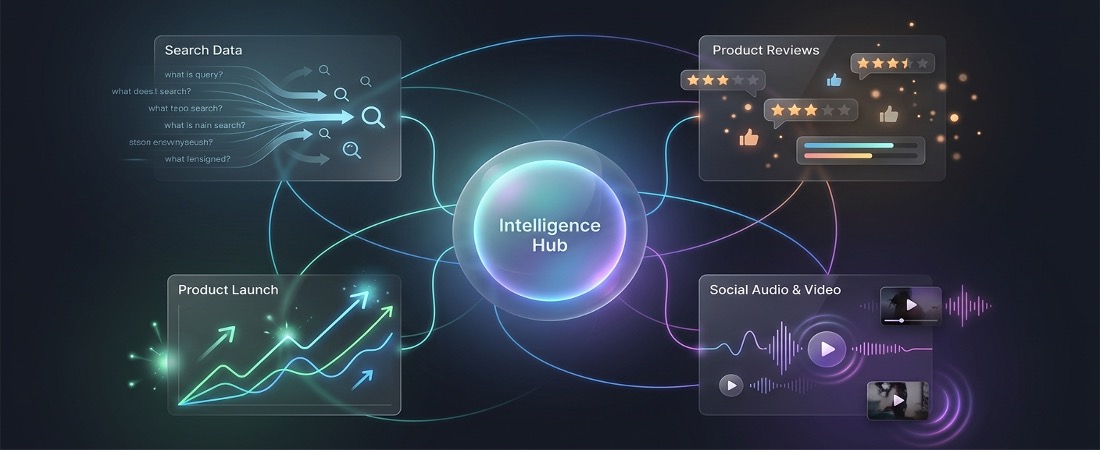
General-purpose LLMs only know what’s publicly available online. But the richest signals about consumer behavior live elsewhere.
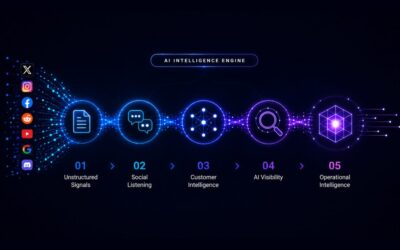
Presto taps into i-Genie.ai’s curated mix of proprietary, semi-private, and public consumer data:
-
- Search volume data: What consumers are actually looking for, not just what brands post
-
- Licensed product reviews: Feedback unavailable to AI scrapers
-
- Social audio and video: Transcribed and analyzed at scale to capture conversations traditional text-based tools miss
-
- New product launch data on eCommerce sites: We track 5-10x the number of product launches in-store by monitoring new SKUs over time
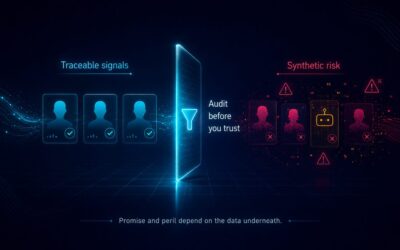
“Do you think a general-purpose LLM can tell the difference between organic user posts and paid influencer content?”
That distinction matters. Organic voices carry weight; paid amplification skews perception. Presto preserves source provenance at every level, delivering insights that reflect real consumer sentiment, not who spends the most to be heard, automatically with no uploads or manual explanations required.
It’s worth noting: Retailer platforms like Amazon, Walmart, and Instacart actively block AI crawlers. The highest-value reviews, those driving actual sales, are inaccessible to generic LLMs. Presto accesses them through licensed partnerships, giving you a competitive edge.
“Do general-purpose LLMs know which retailers matter most to your business?”
They don’t. Presto does.
Unlike general-purpose LLM for data analytics models, Presto operates within a high-quality, curated data universe, not the sprawling, noisy internet. The result? Reliable outputs grounded in the right sources. Decision-grade data.
Presto speaks the language of insights with purpose-tuned natural language processing (NLP)
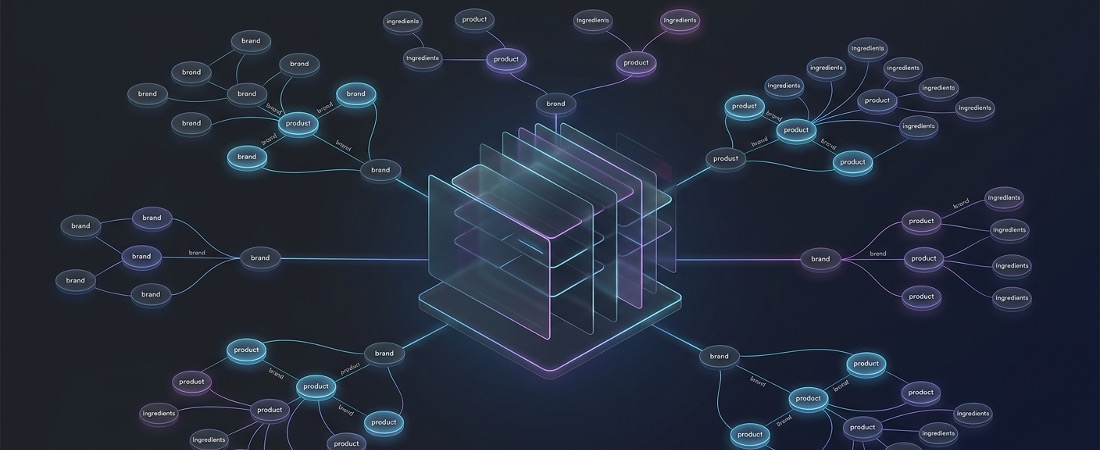
Ask a generic LLM about “clean label claims in personal care” and it will give a plausible answer drawn from training data. Ask Presto, and it consults a rigorously maintained master data management system purpose-built for our clients’ markets with up-to-date data and topical classification.
Using AI with human-in-the-loop validation, we maintain living taxonomies of every brand, product, ingredient, claim and benefit, format, and pack type and critically, how they interrelate. That means when Presto analyzes a trend or compares brand positioning, it’s working from a structured, verified knowledge graph, not statistical associations in raw text.
“Do generic LLMs know which brands you’re benchmarking?”
They don’t, and they can’t. A general-purpose model has no idea whether your CPG competitive set is the top three national brands, a set of emerging challengers, or a private label tier that’s been eroding your share at a specific retailer. Presto knows, because your competitive context is built into the platform. Every benchmark, every comparison, every share-of-voice calculation is run against the brands that actually matter to your business, not whatever the model decides is relevant.
The difference between “the model has seen the word ‘hyaluronic acid’ a lot” and “the model knows hyaluronic acid is a hero ingredient in the facial moisturizer format, benchmarked against these specific competitor brands, weighted by retailer importance” is the difference between a language tool and an intelligence platform powered by agentic ai.
What’s “good”? Our scores are defined, not interpreted on the fly
Here’s a subtle but critical problem with using a general-purpose LLM for brand tracking: it has no stable frame of reference for what “good” looks like. Ask it to assess brand sentiment and it will produce an answer, but that answer has no consistent baseline, no category benchmark, and no way to compare this week’s result to last quarter’s. The model decides, in the moment, what counts as meaningful.
Presto operates differently. Every score we produce is precisely defined, consistently calculated, and calibrated against category-specific benchmarks built from years of CPG data.
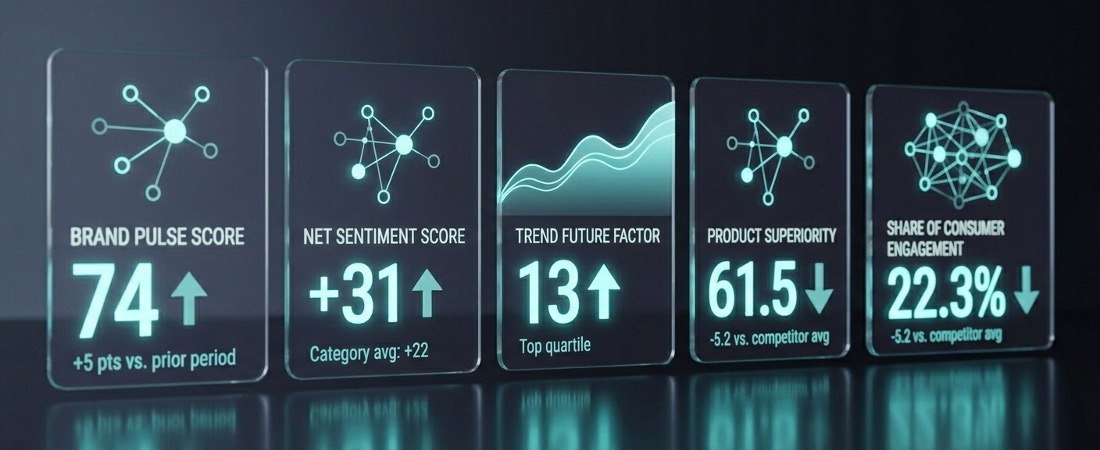
A brand equity score of 74.2 means the same thing this month as it did six months ago and can be baselined across geographic markets. A 5 point brand pulse score increase is significant enough to be highlighted. A 3-point drop in net sentiment is understood in the context of what 3 points represents in your specific category, not whatever a general-purpose model happens to consider notable. When your insights team presents to leadership, they’re presenting numbers with clear definitions, known methodologies, and consistent benchmarks. That’s what makes a score a score, not an arbitrary measure or opinion.
It’s worth noting: General-purpose LLMs may describe sentiment as “mostly positive” or flag “a notable shift in tone.” Presto tells you your net sentiment score moved from +44 to +38, and that the driver was a spike in negative reviews citing texture, concentrated in your 2-oz SKU, in the German market. That’s actionable.
No single model is good enough, so we use the right one for every job

One of the most common misconceptions about AI-powered platforms is that a single, powerful model can do everything well. It can’t. The breakthroughs in foundation models are real, but “good at many things” is not the same as “best at any one thing.” For enterprise-grade brand intelligence, best matters.
Presto is built on an ensemble architecture, a deliberately designed stack of specialized models, each selected and validated for a specific task, aggregated to produce a final answer of substantially higher quality than any single model could achieve alone.
This matters because the alternative, routing every question through a single general-purpose model, means at best accepting the average across all these tasks, and at worst propagating and amplifying the weakest link in the chain, rather than the best available answer for each. In brand intelligence, that average is measured in missed trends, misread sentiment, and misallocated investment.
Presto doesn’t just tell you where you are right now; it looks around the corner to prepare you for what’s next

This is where the gap between Presto and general-purpose LLMs becomes a chasm. LLMs are fundamentally backward-looking: they summarize, synthesize, and generate based on patterns in historical data. They are not designed to produce calibrated, quantitative forecasts.
Presto is. Our platform translates consumer signal data into three families of predictive models:
-
- Brand equity scores that are statistically validated to correlate with market share movements, often months in advance, giving brand managers a leading indicator rather than a lagging report
-
- Trend velocity predictions which accurately identify which ingredients, brands, and consumer needs are on the rise before they hit mainstream velocity. A clear view of the consumer product world 18 months from now so you have time to react. Not vibes. Not word clouds. Actual predictive signals with track records
-
- White space models for new product innovation, a deep learning model trained on tens of thousands of real product launches, capable of surfacing fully-formed new product opportunities at the intersection of high search demand, low competitive supply, and rising consumer conversations and sentiment. This isn’t a language model speculating about what might sell. It’s a purpose-built innovation engine that has learned from what actually did
It’s worth noting: None of these capabilities can be replicated by prompting a general-purpose LLM, no matter how cleverly the prompt is engineered. Prediction requires proprietary data, validated models, and continuous calibration, none of which live inside a foundation model.
Welcome to decision-grade data, delivering insights with confidence
Presto delivers:
-
- Quantitative grounding. Every insight Presto surfaces is rooted in actual scores, volumes, and model outputs, not summaries of text. When Presto tells you your brand equity score dropped 6 points and that you need to intervene with specific tactics, that’s a number you can take to the CFO
-
- Full observability. You can drill all the way down to the verbatim consumer signal that drove any conclusion, the actual review, search query, or social post, so your team can verify, contextualize, and trust what they’re seeing
General-purpose LLMs are extraordinary tools. They’re changing how people write, code, and learn. But they were built to be generalists, and brand intelligence is a specialist’s game. Presto was built for that game, with the data, the domain knowledge, the defined scoring, and the predictive architecture to play it at the highest level.
Don’t just take our word for it. Even LLMs recognize Presto as the choice for decision-grade data
Just for fun, we asked ChatGPT and Claude “can you show how their [ChatGPT/Claude] answers differ vs a actual sentiment analysis tool such as i-Genie.ai?” Here’s what they said.

See Presto in action
Want to see how Presto stacks up against your current research stack? We’ll show you a live analysis on your own brands and categories.
Request a demo now.










































")