The pitch is irresistible. Skip the six-week fieldwork cycle. Forget the $200K budget line. Feed a brief into an AI platform and receive 10,000 simulated consumer responses by morning. Speed in hours rather than weeks, a fraction of the fieldwork cost, infinite sample size at zero marginal cost, and a clean methodology free of interviewer bias. For insights teams under relentless pressure to deliver faster and cheaper, synthetic panels feel like the answer they’ve been waiting for.
The reality is more complicated and understanding where that complication lives is the difference between a powerful research tool and an expensive mistake dressed up in confidence intervals.
What synthetic panels get right, and where they don’t
Before unpicking the problems, it’s worth being honest about what synthetic panels genuinely deliver. The appeal is real, and so are the limitations.

The strengths explain the growth. The weaknesses explain the expensive mistakes. The rest of this piece is about telling the two apart.
The synthetic data fraud problem everyone is avoiding
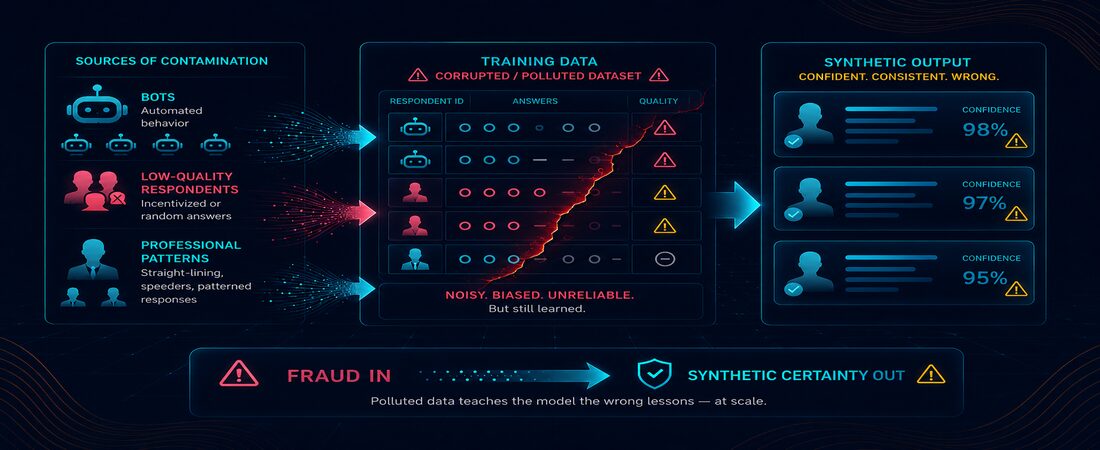
Before we even get to the AI question, we need to confront the uncomfortable truth about the data that trains synthetic panels in the first place.
The survey ecosystem, in other words, is already broken. Now consider what happens when a synthetic panel is trained on that ecosystem. The contamination doesn’t just persist, it gets codified, amplified, and served back with the appearance of statistical rigor.
As Mark Ritson noted in his Marketing Week column, synthetic data carries “gigantic implications” for the research industry.
The ability of AI to answer accurately for — and instead of — actual consumers has gigantic implications, many of which are still beyond us.
He’s right. But those implications cut both ways. When the signal going in is polluted, the signal coming out isn’t just wrong, it’s wrong with 95% confidence intervals. That’s the nightmare scenario the industry isn’t talking about loudly enough.
The nightmare scenarios are concrete and worth naming. A synthetic panel trained on fraud-heavy panels can systematically over-report trial intent, inflating a new product launch forecast by 35%. Bot responses cluster around mid-scale ratings, so the model quietly learns ‘average everything’ as its default human response. Personas built from click-farm pools end up simulating consumer behaviour in markets those respondents never lived in. And a brand makes a $50M reformulation decision on NPS scores that were corrupted before the model ever saw them.
Three ways synthetic panels are built, and where each one breaks
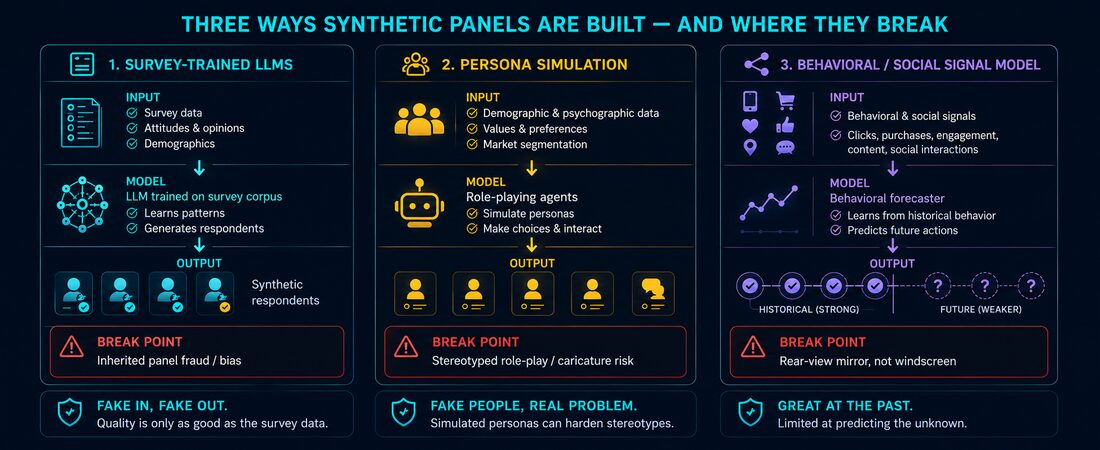
Most synthetic panels reach the market through one of three paths.
Survey-trained LLMs fine-tune a model on existing survey corpora. The problem is that they inherit every bias, bot response, and social desirability artefact baked into that data. Garbage in, synthetic garbage out, dressed up with a four-decimal-place confidence score.
Persona simulation prompts an LLM to ‘act like’ a demographic segment. This is essentially asking a model to play a character based on its own stereotyped representation of that group. The result is frequently a caricature, not a human – demographic simulation often runs shallow, and the outputs are black-box and difficult to audit, which is a problem when a strategic decision rides on them.
Social and behavioral data panels (like those built on Numerator’s receipt-level transaction data) are a meaningfully different animal. They start from what people actually did, not what they said they’d do. For repeat purchase prediction and category switching behavior, they perform well. But they are, fundamentally, rear-view mirrors. A Numerator-style panel can tell you with high precision that a household segment switches from Brand A to Brand B when Brand B’s price drops below $4.99. It cannot tell you how that household would respond to a brand that didn’t exist in its purchase history.
That distinction matters enormously for innovation research, which is precisely where brands most want to deploy synthetic panels, and where they are most structurally unfit for the job.
Where synthetic panels genuinely earn their place

None of this means synthetic panels should be abandoned. It means they should be used for the right jobs.
There are genuine strengths here. Questionnaire optimization (testing survey flow and question wording before going to field) is low-stakes and high-value. Early-stage concept screening, the “does this resonate at all?” filter before committing to real fieldwork, is a sensible use case. Stable attitudinal tracking for established brands with long research histories works reasonably well, because the underlying attitudes are well-documented and slow-moving. Research augmentation is another safe lane: generating hypotheses, crafting discussion guides, and simulating edge-case consumer profiles to stress-test ideas before real respondents are involved.
Where the risk profile climbs sharply: price sensitivity testing (synthetic consumers are notoriously poor at expressing genuine price pain), advertising pre-testing (they miss emotional resonance and cultural relevance that real humans feel), and new product launch forecasting (they pattern-match to historical analogues and systematically distort innovation signals). High-stakes strategic calls like M&A due diligence, major reformulations, brand repositioning and $50M+ media investments should never rest on synthetic panel data alone.
The rule of thumb is worth internalizing: treat synthetic panels the way you would treat secondary research. Invaluable for orientation, hypothesis generation, and directional filtering. Insufficient on its own for decisions where being confidently wrong is more dangerous than not knowing.
What best-in-class AI market research tools actually look like

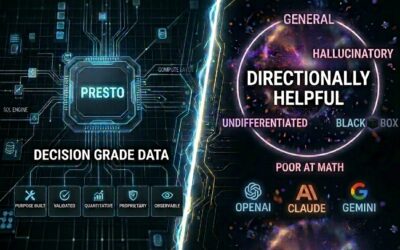
The vendor landscape is not homogeneous. The best synthetic panel providers combine multiple data modalities, behavioral purchase data, organic text from reviews and community forums, digital engagement signals, and treat survey data as one input among many rather than the foundation. They maintain robust fraud detection at data ingestion, are transparent about training composition, validate synthetic outputs against real-world panels before deployment, disclose significant divergences, and flag low-confidence outputs rather than smoothing them over.
A useful test when evaluating any vendor: ask them what data trained the model, how the demographic composition of training inputs breaks down, and what their validation methodology looks like against real-world panels. If the sales deck leads with “10 million synthetic respondents available immediately” and contains no discussion of those questions, walk away.
The panel fraud problem is worsening, not improving. According to Sumsub’s 2025–2026 Identity Fraud Report, advanced fraud attacks surged 180% in 2025 as generative AI enabled more sophisticated fake identities and autonomous bots. Any synthetic panel vendor that cannot demonstrate active fraud detection in their training pipeline is compounding your data quality problem, not solving it.
The question every market research tool needs to answer
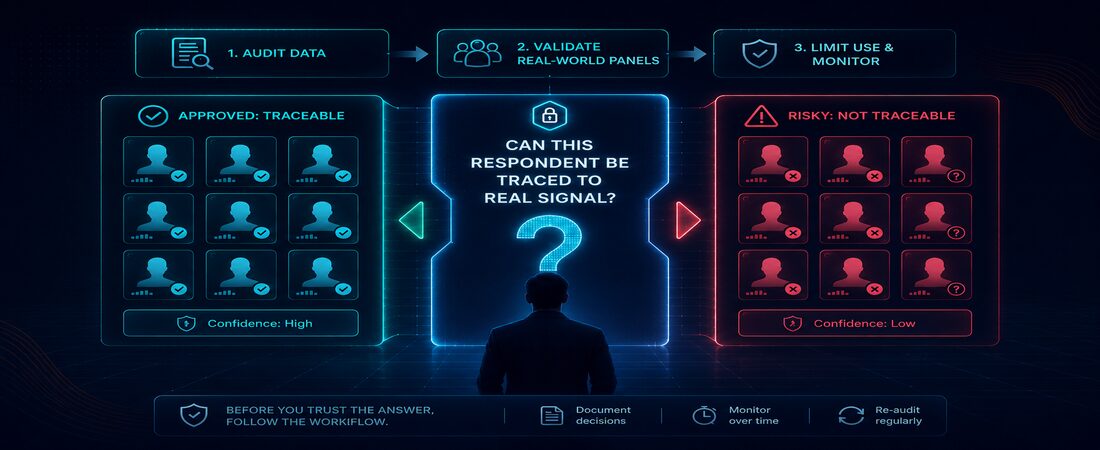
The enthusiasm for synthetic panels across the insights industry is entirely understandable. Traditional survey costs are punishing. Timelines are agonizing. The fraud problem is real and accelerating. Synthetic panels solve some of these problems, some of the time, in the right hands.
But the structural question remains unanswered by most of the platforms currently on the market: if the consumer your model is simulating was trained on data from a bot-ridden panel, a click-farm respondent pool, or a demographically skewed slice of vocal online voices… did that consumer ever actually exist?
The most dangerous outcome in research isn’t uncertainty. Uncertainty prompts caution. The most dangerous outcome is a wrong answer delivered with the appearance of certainty, and that is precisely what a poorly built synthetic panel is capable of producing at scale.
Used with clear eyes about its limitations, synthetic research is a genuinely useful tool. Used as a wholesale replacement for rigorous human research on high-stakes decisions, it’s a liability dressed as an efficiency gain.
The seductive shortcut, as it turns out, still requires you to know where you’re going.
A different architecture entirely: How i-Genie.ai‘s consumer insights analytics approach the problem
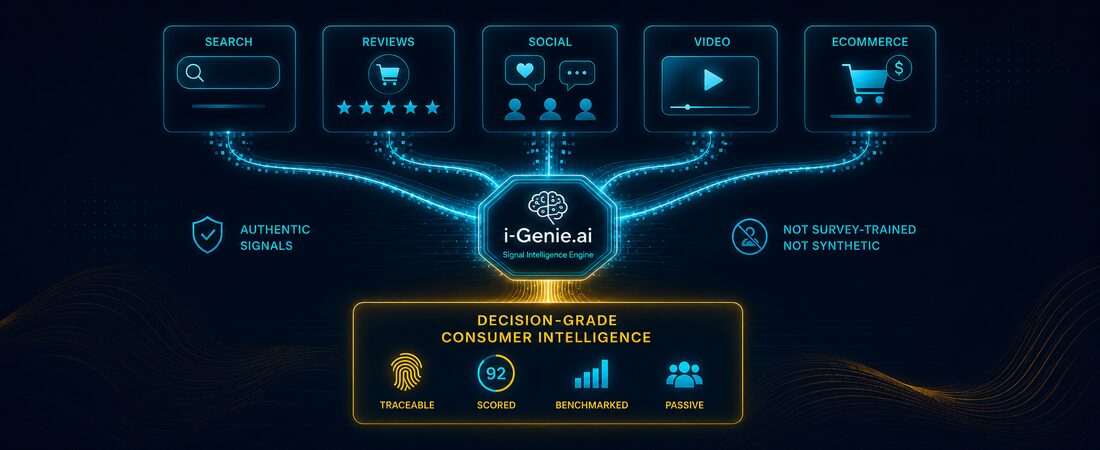
i-Genie.ai was built on a fundamentally different premise: that the richest consumer signal doesn’t live in surveys at all. Rather than training on a bot-contaminated panel ecosystem, i-Genie.ai synthesizes hundreds of billions of data points from where consumers are already talking and acting like search behavior, eCommerce reviews, social conversations, and video content, passively, without a survey in sight.
Each source is inherently cleaner than anything survey-trained: search reflects what people actually look for, licensed reviews capture post-purchase truth, and social signals surface sentiment at a scale traditional tools miss. None carry the click-farm distortion that corrupts synthetic panel models.
This matters especially when you consider how even the best behavioral panels (those built on actual purchase data rather than surveys) still hit a structural ceiling on the questions that matter most for growth.

They score strongly on repeat purchase prediction and category switching, reasonably on price sensitivity and promotional response, and weakly on new brand trial propensity and genuinely novel concept adoption. For new brand trial in particular, the honest verdict is that the best available approach is a hybrid: behavioural segmentation to identify the right target pool, combined with real human qualitative and quantitative research to assess the specific proposition.
Behavioral panels are extraordinary rear-view mirrors but for innovation research, where brands most want predictive power, they’re structurally blind. i-Genie.ai’s multi-source model is designed to close that gap.
The result is decision-grade data. Outputs grounded in consistent scoring, traceable to individual consumer signals, and calibrated against real category benchmarks. For brands under pressure to move faster on insights, i-Genie.ai offers a genuine third path: not the slow survey cycle, and not the false precision of a synthetic panel trained on corrupted data but AI-powered intelligence built on the authentic voice of the consumer.










































")